

最初,会在收集到有限数量的数据后,于每一周前一天的同一小时计算基准平均值。 例如,在记录两天之后,通过计算连续两天同一时段的每小时累加,计算上午 9:00 到上午 10:00 的基准平均值。
最终,有更多数据后,会自动改变计算方法。Data Aggregator 通过计算一周内同一天前可用天数的每小时样本的平均值,来确定“正常”性能。 然后,这种方法会考虑使用率中的星期日期模型。 此方式生成更趋于“正常”的近似值,其可以减少未命中违规和误报事件的生成数目。 在上述同一个示例中,记录三周后,通过计算这三个星期内三个星期一的上午 9:00 到上午 10:00 的每小时累加数据的平均值,来确定基准平均值。
注意:默认情况下,在至少一周内三天中同一小时的数据样本适用于过去 12 个周时,会出现这种自动改变。 当所需的数据点数量不再可用时,Data Aggregator 自动切换回到每天同小时计算方式。 这些默认设置是可配置的。 有关更改这些默认设置的信息,请参阅《Data Aggregator REST Web 服务指南》。
计算基准平均值是出于事件和报告生成目的。
示例:计算 CPU 使用率的同小时平均值和总体标准偏差
下例显示,在星期一、星期二和星期三有 3 个上午 2:00 数据点时,将针对特定设备的 CPU 使用率计算“同小时”平均值(中间数)和总体标准偏差。
请执行以下步骤:
天: 星期一 星期二 星期三
平均数(平均值)CPU 利用率: 76 65 10
计算总体平均数的公式如下所示:
总体平均值 = 数据点值之和除以数据点总数/数量。
此示例的公式如下所示:
(76+65+10)/3
总体平均数= 50.33
此示例的差值是:
25.67 14.67 -40.33
此示例的平方值是:
658.78 215.11 1,626.778
此示例的平方的总和是 2,500.67。
此示例的结果是 833.56。
该示例的平方根为 28.87。
该示例的标准偏差为 28.87。
下表说明每天比率数据的每小时平均值(平均数)、每小时平均值的平均值(平均数)和同小时的每小时平均值的总体标准偏差:
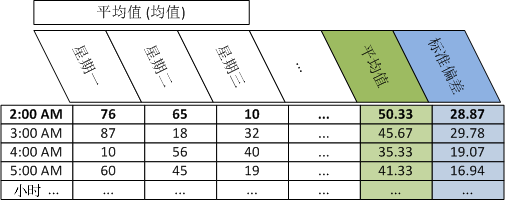
示例:计算 CPU 使用率的星期中同天同小时平均值和总体标准偏差
下例显示,在三个星期一上午 2:00 有 3 个 数据点时,将针对特定设备的 CPU 使用率计算平均值(中间数)和总体标准偏差。
请执行以下步骤:
星期一: 1 2 3
平均数(平均值)CPU 利用率: 76 4 6
计算总体平均数的公式如下所示:
总体平均值 = 数据点值之和除以数据点总数/数量。
此示例的公式如下所示:
(76+4+6)/3
总体平均数 = 28.67
此示例的差值是:
47.33 -24.67 -22.67
此示例的平方值是:
2,240.44 608.44 513.78
此示例的平方的总和是 3,362.67。
此示例的结果是 1,120.89。
该示例的平方根为 33.48。
该示例的标准偏差为 33.48。
下表说明每天比率数据的每小时平均值(平均数)、每小时平均值的平均值(平均数)和星期中同天同小时的每小时平均值的总体标准偏差:
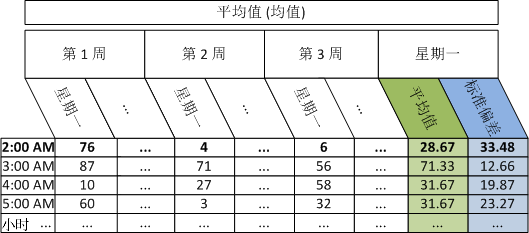
示例:与正常值偏差,使用 CPU 使用率的星期中同天同小时平均值和总体标准偏差
假设 Data Aggregator 每 5 分钟轮询 CPU 使用率数据一次。 您可以定义事件规则,在 CPU 使用率大于单个 5 分钟轮询间隔的均值之上的某个标准偏差时生成事件。
在此示例中,将事件规则持续时间以及窗口设置为 5 分钟。
计算何时生成事件的公式如下所示:
CPU 使用率 = 平均值 + 1(标准偏差值)
因此,之前一周内同一天同一小时(星期一早晨 2:00)的替换均值和标准偏差值如下所示:
CPU 使用率 = 28.67 + 1 (33.48)
CPU 使用率 = 62.15
因此,如果 CPU 使用率在星期一上午 1:05 和上午 2:00 之间超过 62.15 的持续时间为单个 5 分钟轮询时间间隔,便会生成事件。 此事件表示 CPU 使用率偏离正常值的持续时间为该时间段。
示例:在趋势图视图中检查 CPU 使用率事件
假设 Data Aggregator 每 5 分钟轮询 CPU 使用率数据一次。 在此示例中,您想让系统在其中一个业务关键服务器上的 CPU 使用率低于预期水平时发出报警。 您可以定义事件规则,在 CPU 使用率大于单个 5 分钟轮询间隔的均值之上的某个标准偏差时生成事件。
仅供说明,假定从星期一上午 12:00 到星期日上午 12:00,CPU 使用率是 50%。 从星期日上午 12:00 到星期一上午 12:00,CPU 使用率下降到 10%。 您预计到此次使用率会下降。 但是,在 Data Aggregator 开始计算基准平均值时,系统会在 CPU 利用率下降到 10% 时生成事件。 当 CPU 利用率返回到 50% 时清除事件。 由于起初在系统收集限量的数据时会计算每天同一小时的基准平均值,而不考虑星期日期使用率的差异,因此会生成错误事件。 Data Aggregator 预期 CPU 使用率总是保持 50%。
在三周之后,便可提供一周内三个同一天同一小时数据样本,基准平均值的计算方法也会随之改变。 Data Aggregator 通过计算一周内相同天数的每小时样本的平均值,来确定“正常”性能。 Data Aggregator 现在预期 CPU 使用率在每个星期日的上午 12:00 到星期一上午 12:00 达到 10%。 将不再生成于之前每个星期日上午 12:00 生成的错误事件。
下列视图演示了最初如何计算每天同一小时的基准平均值。 有更多数据后,会自动改变计算方法。 Data Aggregator 会计算一周内同一天的每小时样本的平均值。
此视图还演示了在计算发生改变时不再生成错误事件。
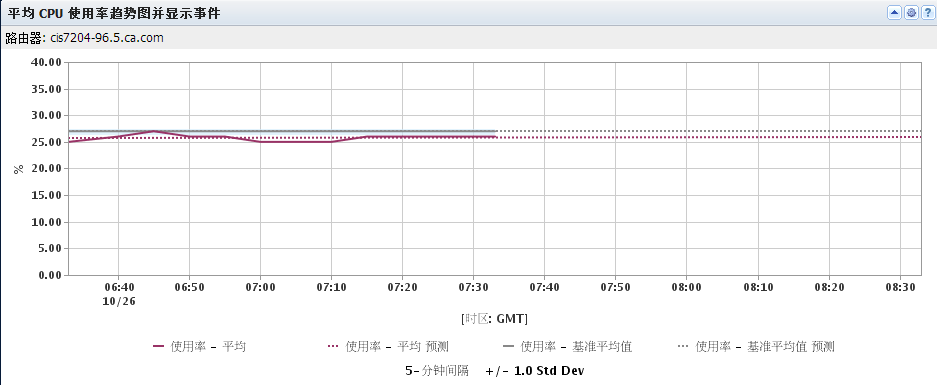
|
版权所有 © 2014 CA Technologies。
保留所有权利。
|
|